






真核生物中超过三分之一的蛋白质含有内在IDR(IDRs),这些区域在长度、组
成、分子特性和生物学功能上极为多样。尽管缺乏明确的结构特征,IDR仍能通过与其他分子的特异性相互作用调控多种细胞过程,其作用模式包括从短线性基序的刚性互作至“模糊结合”等多种机制。许多功能性IDR仅需具备一般组成性的特性而无须保守残基。在调控mRNA稳定性和翻译的RNA结合蛋白(RBPs)中,IDR尤其重要。IDR可通过与翻译起始因子或mRNA降解酶等效应蛋白互作直接影响mRNA表达,但即使功能相似的IDR也存在长度和组成的显著差异,导致其序列-功能关系难以归纳。因此,亟需对功能性IDR开展全局性系统分析,以揭示调控型RBP塑造mRNA动态的普适机制。
2025年4月,加州大学伯克利分校分子与细胞生物学系的Nicholas T. Ingolia课题组和Joseph H. Lobel在Nature发表了名为Deciphering disordered regions controlling mRNA decay in high-throughput的文章,作者建立了通过荧光筛选调控mRNA活性的IDR的高通量筛选方法,利用这种方法对2871种蛋白的共47000个片段进行了筛选;之后对筛选得到的数百个具有调控功能的IDR进行诱变并筛选,结合机器学习,探究影响其功能活性的复杂分子特征模式,阐释IDR如何控制mRNA表达,并揭示了无结构蛋白质发挥功能的更广泛原理。

作者建立了一种基于荧光的检测方法,在芽殖酵母中监测IDR如何调控mRNA的翻译与降解。该方法表达了一种编码黄色荧光蛋白(YFP)的mRNA,并在其3′非翻译区(UTR)中嵌入boxB发夹结构,通过将待测蛋白与λN肽(可识别boxB发夹)融合,将候选蛋白锚定至此报告mRNA上。能够促进mRNA降解或抑制翻译的锚定融合蛋白会降低YFP信号。作者通过分选和高通量测序 (Sort-seq) 测量该蛋白质组的无序肽库的调节活性,根据细胞的 YFP:RFP 比率分为四个大小相等的组,并对每个分选亚群中的片段进行测序,并根据每个片段的分布计算每个片段的活性评分,并将评分为≤-1的无序肽段定义为抑制片段 ,使用该阈值定义了源自 395 种不同蛋白质的 900 个抑制片段。
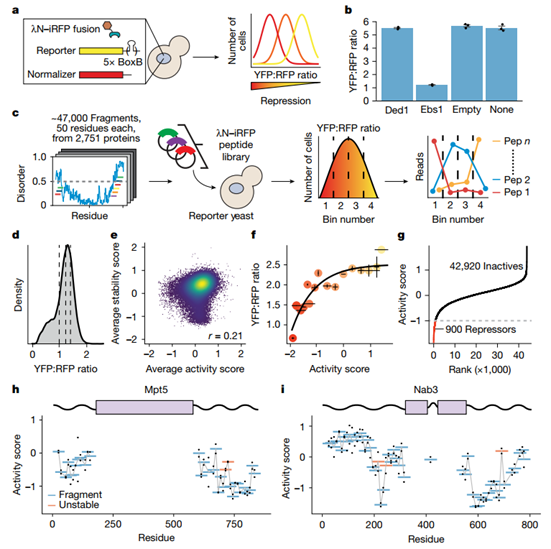
图1.高通量解析IDR的转录后调控活性
真核生物中的大多数 mRNA 降解都是通过一个多步骤过程进行的,首先是 CCR4-NOT 复合物中的 Ccr4 和 Pop2 脱烯化酶降解 poly(A)尾部,触发 Dcp2 的脱帽作用,最后导致mRNA降解。针对抑制片段的GO分析显示,它们显著富集了转录后抑制相关的功能注释,其中去烯基化依赖性降解和 mRNA 不稳定相关功能的强烈富集意味着其中许多抑制片段可能通过募集核酸酶发挥作用。作者通过使用生长素诱导的 degron 系统和吲哚-3-乙酸 (IAA) 处理对 Ccr4、Pop2 或 Dcp2分别作耗竭处理。在三种情况下添加 IAA 都导致该蛋白快速耗竭并导致生长缺陷。针对文库的高通量测算表明,许多无序肽需要 5'–3' mRNA 衰变机制才能发挥作用,耗竭核酸酶相关蛋白会减少 YFP:RFP 比率较低的细胞比例。耗竭条件下的抑制片段活性评分在每种核酸酶耗竭条件下活性都降低。744 个抑制片段中,330 个 (44%) 在至少一种耗竭类型中的活性显著降低,表明其中许多抑制片段依赖于 5'–3' 降解机制来促进 mRNA 周转。
图2.无序的转录后水平调节蛋白通过mRNA的5′–3′降解发挥作用
作者选择了 679 个抑制肽,将每个五个氨基酸基序替换为非任何功能基序的 GGSSG 序列来生成包含变体的新文库,通过 Sort-seq 测量了该文库的活性和稳定性分数,并发现与蛋白质组全文库的测量结果非常吻合。通过将每个突变筛选图谱拟合为双态隐马尔可夫模型来发现功能性基序并量化其影响。此外,作者将突变敏感序列IDR的氨基酸组成与周围的IDR进行比较,发现活性基序富含芳香族和脂肪族残基,这表明这些残基在功能上可能是抑制子活性所必需的。
图3.通过对抑制性IDR的突变筛选发现功能域
作者建立的突变筛选方法可以揭示对 RBP 的内源性调节功能至关重要的基序,并且有助于发现转录后调节因子内的功能基序。作者通过突变筛选在 Tis11 中确定了一个功能基序,该基序在真菌中是保守的,预计会与 Cdc39(人类 NOT1 的直系同源物)相互作用。破坏该基序的表现出与全基因敲除相同的严重生长缺陷,这表明该基序是 Tis11 介导的转录后调控所必需的。eIF4E 结合蛋白 Eap1通过其保守的 Y(X)Lφ基序抑制生产性翻译起始复合物的形成,作者使用这种筛选方法在 Eap1 中发现了两个抑制基序,它们位于 Y(X)Lφ 基序的远端,并且在相关酵母物种中保守。
图4.转录后抑制功能的实现依赖于通过突变筛选出的抑制性基序
作者观察到许多在所有突变中保留活性的抑制片段,例如翻译调节因子 Sgn1 在残基 151-200 之间的突变均未显著破坏活性,这表明没有单个一级序列基序能够驱动该肽的抑制活性,这些区域的突变耐受性可以通过其有多个冗余基序分布于抑制片段解释,或者这些肽的抑制功能更依赖于其整体物理化学性质。
近三分之二的抑制片段(665 个中的 435 个)在蛋白质序列基序被破坏时仍保持活性,这种耐受性与某些IDR基序片段的突变敏感性形成鲜明对比,并揭示了不同类别的功能IDR。作者首先通过逻辑回归方法,仅使用氨基酸含量来预测肽段活性,并为氨基酸组成所驱动的抑制片段和抑制性线性基序分别开发了预测模型,两种模型都实现了很高的预测准确性,表明氨基酸组成是IDR调节活性的主要决定因素。芳香族氨基酸与基序依赖性和组成驱动的抑制片段都密切相关,而酸性氨基酸和赖氨酸与抑制活性呈负相关。作者训练了一个轻度注意力模型来区分组成依赖性抑制片段和非活性无序肽,该模型同样突出了芳香族氨基酸的重要性。
图5.芳香族氨基酸在抑制性IDR中富集
总结
作者通过系统地评估IDR在转录后调控中的功能,阐明了这些没有明确结构的肽段如何控制基因表达。作者发现了一些在IDR内负责调节活性的功能元件,并剖析了它们如何依赖关键核酸酶来驱动 5'–3' mRNA 衰变。此外,对变体文库的分析中,作者发现了IDR的两种功能形式,分别是通过短线性基序形成抑制活性和整体序列组成形成抑制活性。作者通过机器的方法揭示了芳香族氨基酸如何通过其临近序列和氨基酸基序促进抑制片段活性,并详细分析定义了IDR如何调节基因表达关键步骤的分子原理和生化途径。

